Distributors
CN / EN

2025/10/06

# Research on the Skilled Operations of Dual Robots
The dexterous operation of dual robots, due to its high degree of freedom coordination, multimodal perception fusion, and complex skill combination, has become an important research direction in the field of robotics. Although the traditional single-robot operation technology can utilize human demonstration data to guide reinforcement learning methods, it often has difficulty generalizing when it comes to coordinated tasks involving multiple sub-skills. Especially in dynamic scenarios, when the state of the object being operated changes, the operating hand needs to respond according to the real-time three-dimensional posture changes. However, existing methods lack explicit perception of the object's posture and size, resulting in uncoordinated hand movements in dynamic states. Moreover, successful operation tasks require time-aligned combinations of sub-skills, such as the operating hand must establish a stable grip before the active hand starts to rotate. However, existing methods lack mechanisms to coordinate these interdependent sub-processes.
To address these issues, a research team led by Sun Zhengnan from the Industrial Control Institute of the School of Control Science and Engineering at Zhejiang University, including Ye Qi, has conducted the study titled "VTAO-BiManip: Dual Robot Dextrous Manipulation Based on Masked Visual-Tactile-Action Pre-training and Object Understanding". The aim is to achieve human-like dual robot manipulation through multimodal pre-training and curriculum reinforcement learning. This research outcome has been published in the renowned robotics conference IROS.
Figure 1: The left image presents an example of the bottle cap rotation dataset; the middle image shows the simulation results of the bottle cap task using Shadow Hand; the right image demonstrates the real-world deployment using Leap Hand.
# 1. Research Plan:
The research team designed and constructed a VTAO (Visual-Tactile-Action-Object) data acquisition system to capture the demonstration data of human hand operations. This system consists of: 1) Hololens2 for visual data collection; 2) Gloves for tactile and movement collection of both hands; 3) Qingtong visual motion capture system for precisely capturing hand movements and the 6-degree-of-freedom posture of objects; 4) Personal computer for data collection and alignment. Through this system, 216 human hand operation trajectories were collected, involving 26 different bottles, each trajectory lasting 6-17 seconds, totaling 61,684 frames of time-aligned multimodal data.
Figure 2: VTAO data acquisition system for human hand operation
Based on the MAE (Masked Autoencoder) architecture, the research team proposed the VTAO-BiManip pre-training framework. This framework adopts an encoder-decoder structure: the encoder processes visual, tactile and current action inputs, and projects different modal information into latent tokens through an attention mechanism; the decoder reconstructs the original perception modalities, predicts subsequent actions, and estimates the object state. This joint reconstruction mechanism achieves cross-modal feature fusion during the pre-training process, enabling the model to recover the complete environmental interaction from partial perceptual observations.
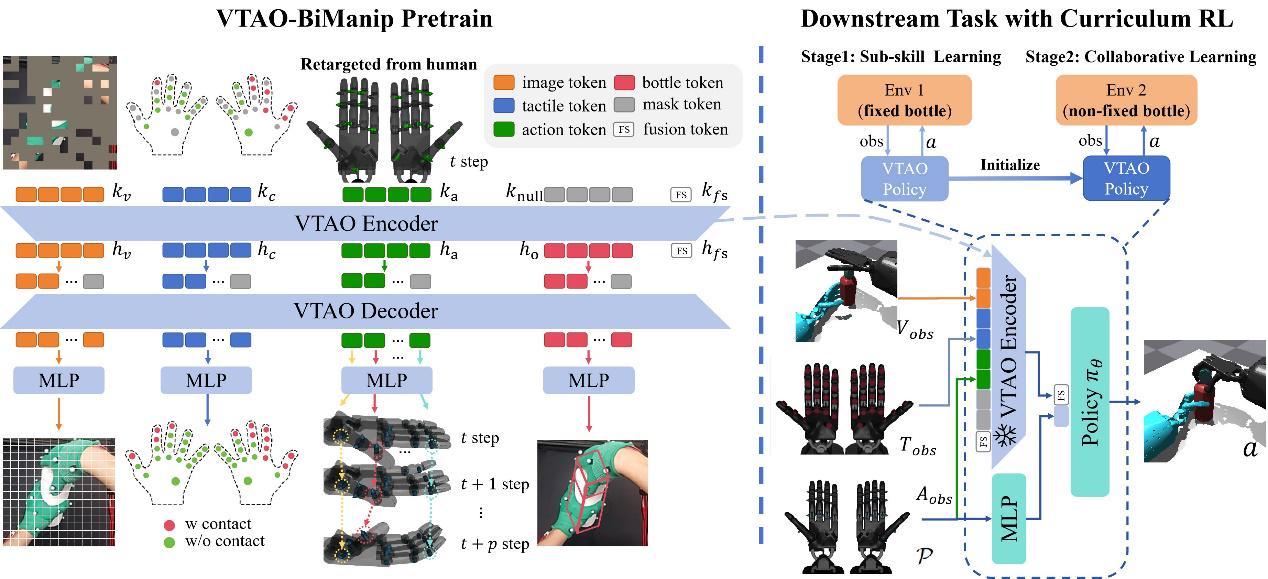
Figure 3: Overview of the VTAO-BiManip pre-training framework and its downstream hand operation and sub-skill collaboration curriculum reinforcement learning
To address the challenges of multi-skills learning, the research team adopted the PPO reinforcement learning strategy and introduced a two-stage course reinforcement learning framework: In the first stage, the bottle was fixed on the table, encouraging the left hand to learn to grasp the bottle and the right hand to learn to unscrew the cap; in the second stage, the bottle was released, forcing both hands to collaborate in the learning of operational skills.
Scheme Innovation and Advantages:
1. The introduction of action prediction and object understanding as supplementary modalities has enabled cross-modal feature fusion.
2. A VTAO data acquisition system was designed, capturing multimodal demonstration data of human hand operations.
3. A two-stage curriculum reinforcement learning framework was proposed, effectively addressing the challenges in the learning of dual sub-skills.
4. The effectiveness of the method was verified in both simulation and real environments, with a success rate exceeding that of existing methods by more than 20%.
# 2. Experimental Verification:
This experiment deployed the task of rotating bottle caps with both hands in the Isaac Gym simulation environment. 15 different bottles from ShapeNet were selected, of which 10 were used for training and 5 for testing. The experiment utilized an Intel Xeon Gold 6326 and NVIDIA 3090 system. During the pre-training phase, the AdamW optimizer was used with a learning rate of 2e-5, and the mask ratios were set at 0.75 for vision, 0.5 for touch, and 0.5 for action. In the reinforcement learning stage, a two-stage curriculum learning approach was employed. The first stage involved 1000 iterations of training, and the second stage involved 3500 iterations, totaling approximately 62 hours.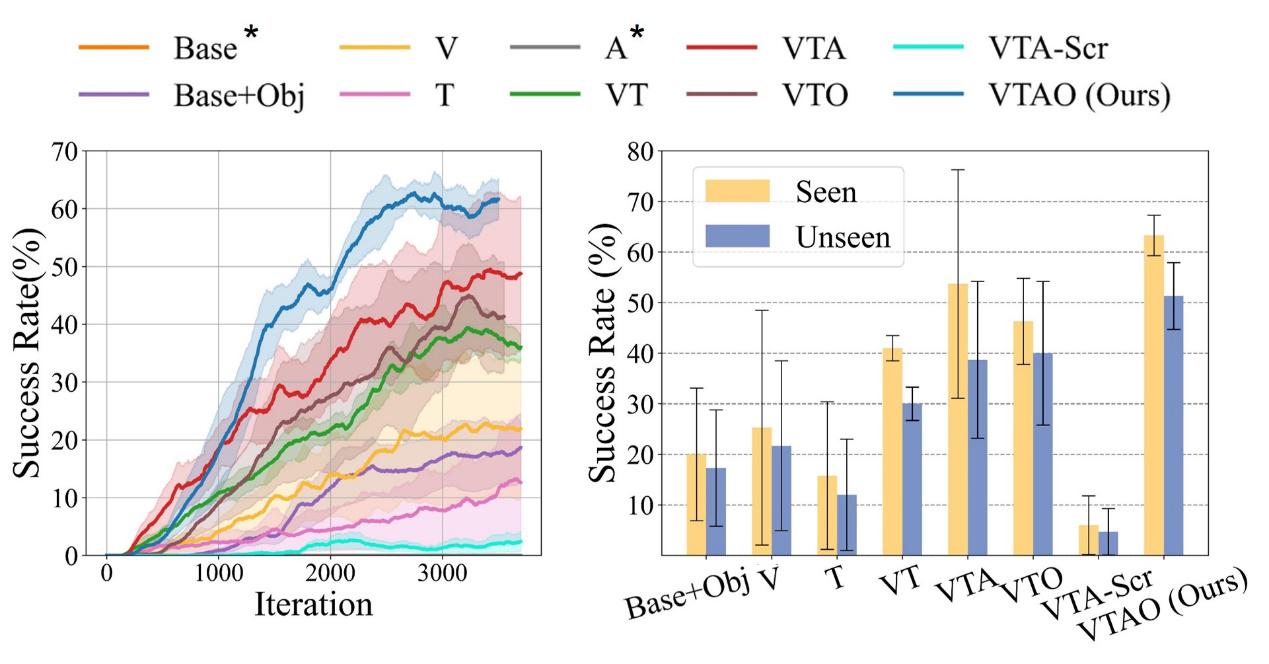
Figure 4: Qualitative results of different pre-training methods in the simulation. Left figure: Training process; Right figure: Evaluation results
By comparing the baseline methods of different modal configurations, the experimental results show: 1) The multimodal joint pre-training method VTA significantly outperforms the single-modal pre-training methods V, T, A, as well as the multimodal method VTA-Scr without pre-training; 2) The performance improvements from VT to VTA (adding action modal prediction) and VTO (adding object understanding) indicate that both action prediction and object understanding can significantly enhance visual-tactile fusion; 3) VTAO achieves the highest success rate by combining the two modalities, indicating that the tasks of action prediction and object understanding have complementary benefits.
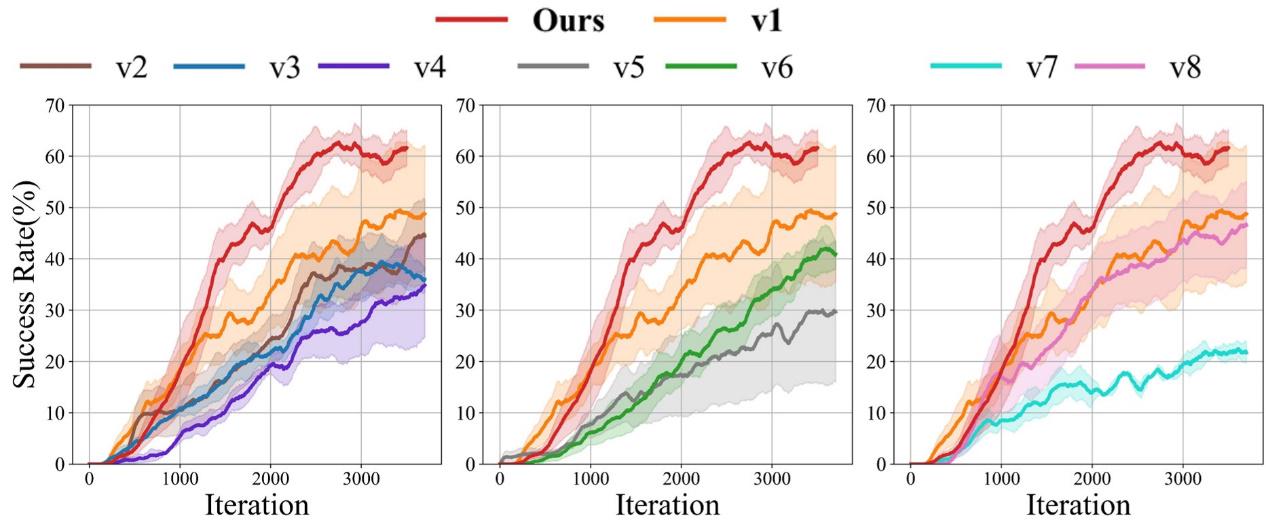
Figure 5: Training process of the ablation study. Left image: Verification of manual operation; Middle image: Ablation of action prediction range; Right image: Ablation of action token quantity
The ablation study further validated the key design choices: 1) Using both hands' data compared to using only the right hand's data, the success rate can be significantly higher regardless of which modality is removed; 2) The action prediction mechanism significantly improves the performance of downstream tasks; 3) The object understanding module is crucial for achieving dynamic operation strategy adjustments based on the state of the target object.
# 3. Experimental Results:
This study demonstrates that the VTAO-BiManip framework successfully achieves dual-handed dexterous manipulation through the combination of multimodal pre-training and curriculum reinforcement learning. This method achieved a success rate of 63% (for objects already present) and 51% (for objects not present) in the simulation environment, outperforming existing methods by more than 20% in terms of performance. The research team also verified the effectiveness of the method in a real environment, as shown in Figure 6.

Figure 6: Our Operating Platform
# IV. References:
1 Liu Y, et al. M2VTP: Masked Multi-modal Visual-Tactile Pre-training for Robotic Manipulation. ICRA 2024.
2 Chen Y, et al. Towards human-level bimanual dexterous manipulation with reinforcement learning. NeurIPS 2022.
3 Qin Y, et al. DexMV: Imitation learning for dexterous manipulation from human videos. ECCV 2022.
4 Rajeswaran A, et al. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. RSS 2018.
5 He K, et al. Masked autoencoders are scalable vision learners. CVPR 2022.
6 Chen Y, et al. Visuo-tactile transformers for manipulation. CoRL 2022.
7 Li H, et al. See, Hear, and Feel: Smart Sensory Fusion for Robotic Manipulation. CoRL 2023.
8 Zhao T Z, et al. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv 2023.
9 Kataoka S, et al. Bi-manual manipulation and attachment via sim-to-real reinforcement learning. arXiv 2022.
10 Chen Y, et al. Sequential dexterity: Chaining dexterous policies for long-horizon manipulation. arXiv 2023.
11 Nair S, et al. R3M: A universal visual representation for robot manipulation. arXiv 2022.
12 Brohan A, et al. RT-1: Robotics transformer for real-world control at scale. arXiv 2022.
13 Xiao T, et al. Masked visual pre-training for motor control. arXiv 2022.
14 Yuan W, et al. GelSight: High-resolution robot tactile sensors for estimating geometry and force. Sensors 2017.
15 Makoviychuk V, et al. Isaac gym: High performance gpu-based physics simulation for robot learning. arXiv 2021.
# 5. Original Link:
https://arxiv.org/abs/2501.03606
https://suzend.github.io/VTAO-Bimanip/
IROS 2025 Zhejiang University: Research on Dextrous Manipulation of Dual Robots
The dexterous operation of dual robots due to ...





+86-21-56472866 / 13310099680
1190 Nong METACINE (South Gate), Building 1, CHINGMU, Zhengtai Road,Baoshan District, Shanghai
Hot searches: Motion capture, Optical motion capture, Motion capture system robot, Motion capture, Bionic robot, Motion control, Gait analysis, Rehabilitation training action assessment, Animation production, Virtual idol live streaming, Expression capture, Virtual production, Pre-visualization, Performance capture