
 CN / EN
CN / EN
NVIDIA构建框架,可以只使用视频输入生成动作捕捉动画
Source:
2022
May. 20
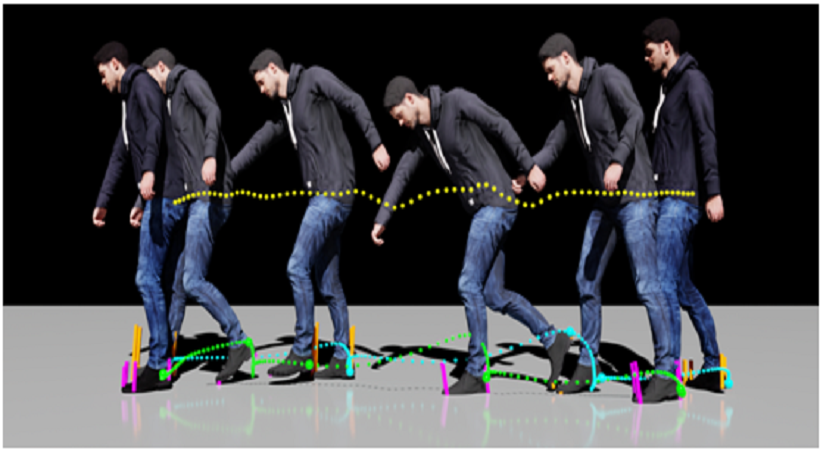
研究人员利用人工智能从视频输入中捕捉单个动作,并将其转换为数字化身。提出了一种仅使用视频输入的动作捕捉方法来改进过去的动作捕捉动画模型。这个新系统不需要以前使用的昂贵的动作捕捉硬件。由于网络上有大量的视频资源,这项工作有望导致更可伸缩的人体运动合成。
现有的运动捕捉方法需要精确的运动捕捉数据进行训练,而训练成本较高。通过新系统,研究人员可以通过视频输入捕捉人工智能的个人动作,并将其转换为数字化身。在本文中,研究人员引入了一种新的框架,在不使用运动捕捉数据的情况下,从原始视频姿态估计训练运动合成模型。该框架还通过接触不变量优化(包括接触力的计算)来加强物理约束,从而细化噪声姿态估计。
这样的优化可以产生修正后的3D姿势和运动,以及相应的接触力。物理修正运动的结果明显优于先前在姿态估计方面的工作。

然后,提出的框架直接从单眼RGB视频中训练物理上可信的人体运动生成模型,这些视频更广泛地可用。
然后,他们训练一个时间序列的生成模型的精炼姿态,并综合未来的运动和接触力。结果表明,通过基于物理的改进,姿态估计的性能显著提高,以及视频的运动合成结果。
这样的框架有望使人们更接近于在虚拟世界中工作和玩耍。有了这个,开发人员可以更经济地动画人类的动作和更多样化的动作。
- Prev:蝙蝠侠与阿尔弗雷德的关系有何不同
- Back
- Next:从血细胞计数到运动捕捉,传感器驱动着以患者为中心的研究