骨骼运动,关节一个接一个
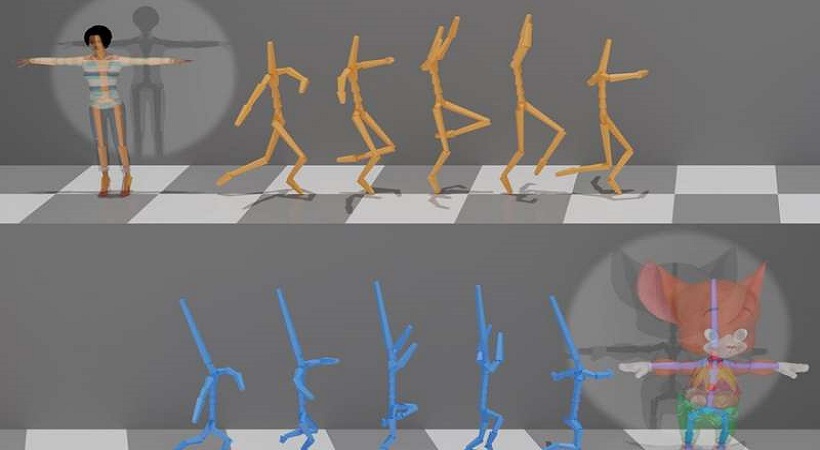
每个人的身体都是独特的,人体自然运动的方式取决于无数因素,包括身高、体重、大小和整体形状。一个由全球计算机科学家组成的团队开发了一种新型的深度学习框架,该框架可以自动精确地翻译人体动作,特别是对大量骨骼结构和关节进行解释。
最终的结果吗?一个无缝的,更加灵活和通用的框架,用于在虚拟世界中复制人体运动。
这个研究团队来自AICFVE、北京电影学院、苏黎世联邦理工学院、耶路撒冷希伯来大学、北京大学和特拉维夫大学,计划在2020年SIGGRAPH期间展示他们的研究成果。会议将于今年8月17日举行,汇聚了从不同角度研究电脑图形和互动技术的专业人士。SIGGRAPH继续作为行业的首要场所,展示前瞻性的想法和研究。虚拟会议现在可以注册了。
在计算机动画和人机交互中,捕捉人体运动仍然是一个新兴的和令人兴奋的领域。动作捕捉(mocap)技术,特别是在电影制作和视觉效果方面,已经使赋予动画角色或数字演员生命成为可能。动作捕捉系统通常要求表演者或演员佩戴一套标记或传感器,以计算捕捉他们的动作和三维骨架姿势。在动作捕捉中仍然存在的一个挑战是精确地在人类骨骼之间转移运动的能力,也被称为“运动重定向”,骨骼的结构可能会因涉及的骨骼和关节的数量而不同。
到目前为止,动作捕捉系统还没有成功地以完全自动化的方式重新定位不同结构的骨骼。错误通常出现在不能指定联合对应关系的位置。该团队着手解决这个特定的问题,并证明该框架可以精确地复制运动重定向,而无需指定变化数据集之间的显式配对。
该研究的资深作者、来自北京电影学院AICFVE的研究员Kfir Aberman分享道:“我们的开发对于在单一模型中使用不同系统捕获的多个动作捕捉数据集至关重要。”“这使得训练更强的、数据驱动的模型成为可能,这些模型对于各种运动处理任务来说是不知道配置的。”
该团队的新运动处理框架包含了专为运动数据设计的特殊操作符。该框架具有通用性,可用于各种运动处理任务。特别是,研究人员利用它的特殊性质解决了动作捕捉领域的一个实际问题,这使得他们的新方法具有广泛的适用性。
“我特别兴奋的是,我们的方法能够将运动编码到一个抽象的、骨架不可知的潜在空间,”Dani Lischinski说,他是这份工作的合著者,也是耶路撒冷希伯来大学计算机科学与工程学院的教授。“未来工作的一个令人着迷的方向将是使基本不同的角色之间的动作转换成为可能,比如两足动物和四足动物。”
除了Aberman和Lischinski,《骨架感知网络深度动作重定向》的合作者还包括peizjo Li, Olga sorkin - hornung, Daniel cohenor和Baoquan Chen。这个团队的论文和视频可以在这里和这里找到。
青瞳视觉编译(如版权问题,请及时联系青瞳进行删除,给您带来的不便请谅解)
- Prev:即将上映的《星球大战中队》游戏的一切
- Back
- Next:迈克尔·尼科诺夫五分钟的动作捕捉